
Introduction
Most enterprises exploring generative AI share a common pattern: strong enthusiasm, a handful of compelling use cases, and then — nothing. Projects stall before a single line of code gets written, or teams skip validation entirely and jump straight into full development.
The consequences are predictable. Gartner estimates that 30% of generative AI projects will be abandoned after the proof of concept phase by end of 2025, due to poor data quality, unclear business value, and cost overruns. Many more never reach PoC at all.
This guide is for business leaders, product teams, and CTOs in healthcare, fintech, retail, and insurance who are ready to test a generative AI idea but need a structured process to avoid those costly missteps.
Key Takeaways
- A generative AI PoC is a short, scoped experiment testing whether an LLM-based approach is technically feasible for your specific business problem
- 3–6 weeks is the right runway — enough to answer one question: can this work with your data, constraints, and use case?
- Key steps: define the problem, assess data readiness, pick RAG vs. fine-tuning, build a minimal prototype, then evaluate against clear KPIs
- PoCs fail due to overbuilding, dirty data, and undefined success criteria
- A successful PoC proves viability — the real build comes next
What Is a Generative AI Proof of Concept?
A generative AI PoC is a focused, time-boxed experiment designed to validate whether a generative AI approach — using LLMs, RAG pipelines, or fine-tuned models — can solve a specific business problem before any commitment to production.
The intended output is not a working product. It's a validated answer to: can this GenAI approach work for us? — tested against real data, real constraints, and measurable criteria.
How It Differs from Adjacent Terms
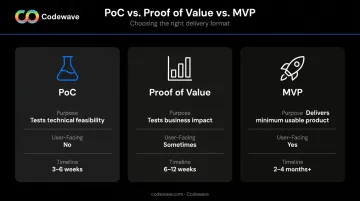
Teams often conflate a PoC with a prototype, MVP, or Proof of Value. Each serves a distinct purpose:
| Term | Purpose | User-Facing? | Timeline |
|---|---|---|---|
| PoC | Tests technical feasibility | No | 3–6 weeks |
| Proof of Value (PoV) | Tests real-world business impact | Sometimes | 6–12 weeks |
| MVP | Delivers minimum usable product | Yes | 2–4 months+ |
A GenAI PoC also differs from a traditional ML PoC. Where traditional ML validates predictive model accuracy on structured data, a GenAI PoC tests language model outputs: relevance, factual accuracy, hallucination rate, and latency — often against messy, unstructured enterprise data. The evaluation criteria are different in ways that matter.
Why Enterprises Build GenAI PoCs Before Committing
Building a full generative AI solution without validating model fit, data readiness, or integration complexity can consume months of engineering time — and still fail at deployment. A PoC surfaces these blockers in weeks, at a fraction of that cost.
Beyond cost control, a GenAI PoC specifically validates things that aren't apparent from architecture diagrams or vendor demos:
- Whether the chosen LLM produces accurate, relevant outputs on your data
- Whether hallucination rates fall within acceptable thresholds for your use case
- Whether response latency meets user expectations
- Whether integration with existing systems is feasible given your infrastructure
The Stakeholder Buy-In Factor
There's a less-discussed benefit: organizational alignment. Compliance teams, legal, and executive leadership are far more likely to engage productively with a working prototype — even a minimal one — than with a slide deck describing what the solution might do.
A PoC converts theoretical skepticism into concrete feedback. Questions shift from "will this work?" to "how do we handle these edge cases?" That shift also reveals the real constraints — data gaps, latency limits, compliance guardrails — early enough to address them without rework costs.
How to Build a Generative AI Proof of Concept
The goal is to answer one feasibility question with minimum scope: does this GenAI approach actually work for your specific problem? That means simulating solution paths quickly, identifying what's worth building, and moving from idea to validated outcome in days — not months.
Before building anything, lock in three constraints: one use case, one data source, one evaluation metric. Anything broader produces results that are hard to interpret and timelines that expand without warning.
Step 1: Define the Business Problem and Success Criteria
Start with a single, specific business problem. Not "improve customer service" — but "automatically summarize insurance claims in under 5 seconds with 90% accuracy."
Define measurable success criteria before building:
- Acceptable factual accuracy threshold (e.g., ≥90%)
- Maximum hallucination rate (e.g., <5% of responses)
- Response latency ceiling (e.g., <3 seconds)
- User satisfaction score if evaluators are involved
Mapping client objectives before technical scoping — using frameworks like the Business Model Canvas — ensures success criteria reflect actual business value, not just technical benchmarks. This step is where most PoCs quietly fail: teams skip to architecture before agreeing on what "good" looks like.
Step 2: Assess Data Readiness
This step is consistently underestimated and consistently causes PoC delays. Audit the data that will feed the model:
- Availability: Is the data accessible, or siloed across systems?
- Quality: Is it clean, consistent, and representative of real-world inputs?
- Format: Is it structured (databases, spreadsheets) or unstructured (PDFs, emails, clinical notes)?
- Compliance: Does HIPAA, GDPR, or SEC regulation constrain how it can be used in model training or retrieval?
For RAG pipelines specifically, unstructured documents need chunking and indexing. A 200-page policy document isn't usable as-is — it needs to be segmented, embedded, and stored in a vector database before retrieval is possible.
Step 3: Choose Your GenAI Approach
Three primary options exist, each with distinct trade-offs:
| Approach | Best For | Trade-offs |
|---|---|---|
| Prompt Engineering | Quick tests with pre-trained LLMs; well-defined tasks | Low cost, fast — but limited customization |
| RAG | Enterprise knowledge retrieval; up-to-date or proprietary data | Moderate setup cost; strong factual grounding |
| Fine-Tuning | Domain-specific language; consistent output format | Higher cost and time; requires labeled training data |

For most enterprise PoCs, RAG is the starting point. It grounds outputs in your actual documents, reduces hallucinations, and doesn't require retraining the base model.
LLM selection depends on use case specifics:
- Proprietary models (GPT-4, Claude, Gemini) offer strong out-of-the-box performance with minimal setup
- Open-source alternatives (Llama) provide more control and on-premise deployment for sensitive data environments
- Healthcare and fintech PoCs are often decided by data residency requirements before capability even enters the conversation
Step 4: Build the Minimal Prototype
Build only what tests the core hypothesis. A minimal working pipeline means:
- Accept a real input (a user query, a document, a form)
- Run it through the selected model or RAG pipeline
- Produce an output that can be evaluated against your success criteria
Deliberately exclude everything else:
- Authentication layers
- UI polish
- Edge case handling
- Secondary use cases
Codewave enforces scope discipline through MoSCoW prioritization and time-boxed sprints, deferring anything that doesn't directly test the core feasibility question. Scope creep at this phase is one of the fastest ways to turn a 3-week PoC into a 3-month project.
Step 5: Evaluate Results Against Defined Criteria
Test the prototype using real or representative data, then evaluate against the success criteria from Step 1.
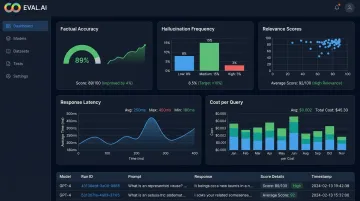
Key metrics to assess for GenAI outputs:
- Factual accuracy — does the output match ground truth?
- Hallucination frequency — how often does the model generate plausible but incorrect content?
- Relevance scores — are retrieved documents (in RAG) relevant to the query?
- Latency — does response time meet the defined threshold?
- Cost per query — is the operational cost sustainable at production volume?
Codewave uses evaluation platforms including TruLens, LangSmith, and Arize AI to assess GenAI outputs across all five dimensions. Document what worked, what failed, and what assumptions held — even a failed PoC produces the evidence needed to make a confident go/no-go call on full-scale development.
Key Factors That Affect GenAI PoC Outcomes
Data Quality and Representativeness
According to IBM, poor data quality is the single most common reason AI projects fail to deliver expected outcomes. Even a capable LLM produces poor results when the underlying data is noisy, incomplete, or unrepresentative of real-world inputs.
Data preparation typically includes:
- Cleaning — removing duplicates, correcting errors, standardizing formats
- Chunking and indexing — structuring data for retrieval in RAG pipelines
- Representativeness checks — ensuring training or retrieval data reflects real-world query patterns
Enterprise teams consistently underestimate this phase — it often consumes the majority of PoC time and budget.
Evaluation Metric Selection
Generic accuracy metrics are insufficient for language model outputs. A response can be grammatically perfect, topically relevant, and factually wrong. Evaluation needs to account for:
- Hallucination frequency (not just accuracy)
- Relevance of retrieved context in RAG pipelines
- Consistency across similar queries
- Latency and cost at realistic query volumes
Stanford's HELM benchmark evaluates LLMs across dozens of scenarios and metrics, making it a practical reference when designing evaluation criteria for complex use cases.
Scope Control and Stakeholder Alignment
PoC scope creep — adding features, expanding to multiple use cases, or shifting success criteria mid-build — is one of the top reasons GenAI PoCs produce inconclusive results. Before development begins, lock in:
- A single, specific problem statement
- Measurable success criteria with agreed thresholds
- Explicit stakeholder sign-off on what a "passing" result looks like
GenAI-Specific Risks
These risks don't appear in traditional software PoCs and need active attention:
- Prompt injection — malicious inputs that manipulate model behavior (OWASP LLM Top 10 covers this extensively)
- Data leakage through model context windows
- Regulatory compliance — FDA oversight for healthcare AI, SEC scrutiny for fintech applications
- Explainability — when outputs must be auditable, black-box model decisions create regulatory exposure

Addressing these factors upfront is what separates a PoC that generates a clear go/no-go decision from one that leaves stakeholders uncertain.
Common Mistakes in GenAI PoC Development
Most GenAI PoCs don't fail because the technology is wrong — they fail because the process around them is. These four mistakes show up repeatedly across teams of all sizes.
Treating the PoC Like a Pre-Product
Adding authentication, multi-use-case support, and polished UI turns a validation exercise into a mini-project. It inflates timelines, raises stakeholder expectations, and buries the core feasibility question under unnecessary complexity.
Assuming Data Is Ready to Use
Teams regularly discover mid-PoC that their data is siloed, access-restricted, or formatted inconsistently. A GenAI PoC won't fix data infrastructure problems. If foundational data issues exist, resolve those before meaningful model testing can happen.
Confusing PoC Results With Production Readiness
A prototype that performs well on clean sample data is not a production-grade solution. Edge cases, adversarial inputs, load conditions, and continuous evaluation requirements all introduce gaps that PoC environments don't surface.
Building a PoC When the Problem Is Already Solved
For well-documented use cases — like an FAQ chatbot on a standard knowledge base — a PoC adds little value and delays time-to-market. Likewise, if internal infrastructure or organizational readiness can't support even a scoped experiment, a readiness assessment should come before any prototype work begins.
Conclusion
A generative AI PoC is the bridge between a promising idea and a production-grade solution. Done right, it reduces financial risk, reveals real technical blockers, and gives leadership something concrete to evaluate before committing to full development.
The principle that determines PoC success or failure is almost always scope: one problem, one dataset, one evaluation goal. Organizations that stay narrow get answers. Those that expand mid-build get inconclusive results and sunk costs.
Codewave builds GenAI PoCs through its ImpactIndex™ model, which ties every deliverable to measurable business outcomes — not just a working prototype. That distinction matters when teams need to justify investment to leadership before full development begins.
Whether the engagement is a 3-week feasibility test or a path to full implementation, the starting point is the same: a clearly scoped problem, a defined success metric, and an honest answer about whether the technology fits.
Frequently Asked Questions
What is a proof of concept in AI?
An AI proof of concept is a small-scale, time-boxed experiment that tests whether a specific AI approach is technically feasible for a defined business problem, run before any commitment to full product development. The output is a validated answer about feasibility, not a deployable product.
What are AI proof of concept development services?
These are professional services where an AI development partner scopes, builds, and evaluates a minimal AI prototype on your behalf. The goal is to validate model fit, data readiness, and integration feasibility without the cost and risk of building a full solution.
What is an example of a generative AI service?
Common examples include LLM-powered chatbots, document summarization tools, RAG-based enterprise knowledge assistants, AI-generated content pipelines, and automated claims processing for insurance — spanning industries from healthcare and fintech to retail.
What is the difference between a GenAI PoC and an MVP?
A PoC tests technical feasibility in a controlled, minimal environment and is not user-facing. An MVP is a deployable product with enough features to deliver value to real users. The PoC comes first, validating the idea before MVP investment is justified.
How long does a generative AI proof of concept take?
A well-scoped GenAI PoC typically runs 3–6 weeks, depending on data availability, integration complexity, and how many model approaches are being tested. Organizations with clean, accessible data and a clearly defined problem can move toward the shorter end of that range.


