Introduction
Worldwide generative AI spending is expected to reach $644 billion in 2025 — a 76.4% jump from $365 billion in 2024. Yet the investment surge has exposed a pricing problem most enterprises weren't prepared for: GenAI costs vary not just by vendor, but by pricing model type, workload shape, scale, and organizational maturity.
According to Deloitte's 2025 AI ROI study, most organizations report achieving ROI on AI projects within 2–4 years — far beyond the typical 7–12 month payback period for technology investments, with only 6% seeing returns within a year.
Choosing the wrong pricing model often costs more than the AI itself. Organizations routinely underbudget for total cost of ownership, select pricing structures that penalize their actual usage patterns, and get blindsided by infrastructure and retraining costs after go-live.
This article covers:
- Actual enterprise GenAI cost ranges
- The five main pricing models and when each makes sense
- Hidden cost drivers most budgets miss
- How to match the right model to your use case
Key Takeaways
- Enterprise GenAI costs range from under $100,000/year for basic deployments to $2 million+ for large-scale custom implementations
- Five pricing models dominate enterprise GenAI: per-seat, token-based, usage credits, reserved throughput, and outcome-based — your workload shape, not the list price, should drive the choice
- Hidden costs routinely add 25–40% on top of vendor quotes, covering data prep, integration, and ongoing model maintenance
- Mismatched pricing models consistently cost more than premium models that align with actual usage patterns
What Does Enterprise Generative AI Actually Cost?
Enterprise GenAI does not have a fixed price—costs vary based on the pricing model chosen, number of users or requests, degree of customization, and AI deployment maturity. Organizations that misunderstand cost structures face painful consequences: underbudgeting for total ownership, choosing pricing structures that penalize their actual usage patterns, or discovering unexpected infrastructure and retraining expenses after launch. 85% of organizations misestimate AI project costs by more than 10%, according to recent industry research.
Understanding where your organization falls in this spectrum is the first step to building an accurate budget. The three tiers below cover the realistic cost ranges at each stage.
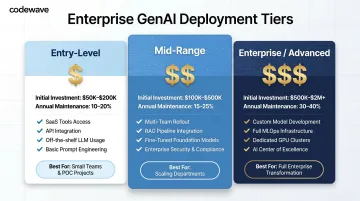
Entry-Level / Basic Deployments
Basic deployments typically include:
- Off-the-shelf SaaS AI tools and API access to foundation models
- Limited user seats or token quotas
- Minimal customization
- Examples: Microsoft Copilot, low-volume API usage for content generation or summarization
Best for: Teams piloting GenAI for a single function before broader commitments. Initial investment ranges from $50,000 to $200,000, with ongoing annual costs running 10–20% of that figure.
Mid-Range / Multi-Use-Case Deployments
Mid-range deployments go beyond single-function pilots and typically include:
- Broader user rollouts across multiple teams
- Integration with existing enterprise systems
- RAG (retrieval-augmented generation) setup
- Basic governance and security controls
Best for: Organizations scaling AI from one department to several. Initial investment typically ranges from $100,000 to $500,000, with ongoing annual costs of 15–25% of initial investment. Common use cases include customer service automation, document processing, and internal knowledge management.
Enterprise / Advanced Deployments
Advanced deployments support mission-critical, organization-wide AI and typically include:
- Custom model development or fine-tuning
- Agentic AI capabilities and MLOps pipelines
- Dedicated infrastructure and compliance frameworks
- Ongoing model maintenance and retraining
Best for: Large enterprises running AI across high-stakes workflows—fraud detection, clinical decision support, autonomous process automation. Initial investment ranges from $500,000 to $2 million, with ongoing annual costs of 30–40% of initial investment. Custom LLM fine-tuning alone adds $100,000–$400,000 in compute and engineering costs. Once you factor in compliance requirements, integration complexity, and retraining needs, total costs can climb well past initial estimates.
The 5 Enterprise GenAI Pricing Models Explained
AI vendors use fundamentally different billing structures because enterprise use cases have fundamentally different shapes. What appears cheaper on a per-unit basis can be far more expensive at scale if the model doesn't match the workload. Understanding these five models is critical to avoiding costly misalignments.
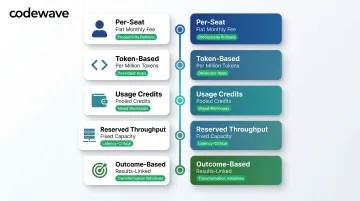
Per-Seat Subscription
This model charges a flat fee per licensed user per month, typically covering a defined set of AI features within a platform—productivity assistants embedded in workplace software, for example. However, "per seat" doesn't always mean unlimited usage. Many plans have hidden usage caps or premium tiers that charge extra once consumption exceeds baseline allocations.
Best for: Organizations enabling broad employee productivity — writing, summarization, meeting assistance — where usage per person is hard to track at the task level. The flat-rate structure keeps budgets predictable and eliminates surprise bills.
Token-Based API Pricing
Cost is calculated per thousand or per million input/output tokens processed. Actual cost depends on prompt design, response length, model tier selected, and request volume, making forecasting harder without detailed workload modeling. All three major providers — OpenAI, Anthropic, and Google — offer 50% discounts for batch processing, fundamentally changing the economics for non-real-time tasks.
Example pricing ranges (per million tokens):
- Frontier models: $5.00–$30.00 output tokens
- Mid-tier models: $2.50–$15.00 output tokens
- Economy models: $0.40–$5.00 output tokens
Best for: Developer-led workloads embedding AI into applications, products, or internal tools with variable usage. Batch processing at 50% discount significantly reduces costs for asynchronous tasks like document analysis, report generation, and data processing.
Usage Credits and Flexible Pools
Organizations purchase a pool of credits consumed across users or API calls, with admins setting spend caps and burst allowances. This hybrid model sits between predictable seat pricing and open-ended token consumption.
Where it fits: Mixed workloads where some usage is predictable and some is bursty. Watch out for credit expiry policies and opaque consumption rules — these can quietly erode value if not negotiated upfront. Always clarify expiration terms, rollover policies, and whether credits apply uniformly across model tiers.
Reserved / Provisioned Throughput
A fixed-cost commitment, billed hourly or monthly, guaranteeing dedicated model capacity and low-latency access on infrastructure shared with no one else.
Ideal workloads: Mission-critical, latency-sensitive applications — real-time fraud detection, production-floor AI, patient monitoring — where unpredictable response times are unacceptable. One real constraint: if demand drops, fixed commitments become wasteful fast. Accurate capacity forecasting is non-negotiable before signing.
Outcome-Based / Value-Linked Pricing
This model ties payment to measurable business results rather than usage volume. Cost scales only when value is delivered, making it structurally the most aligned with enterprise ROI goals.
It's gaining traction because it shifts delivery risk to the implementation partner rather than the buyer. Codewave's ImpactIndex™ works on this basis: clients pay for measurable results, not time or tokens. Typical outcome benchmarks include:
- Productivity gains (measured as hours saved or output per employee)
- Cost reductions (percentage decrease in operational spend)
- Accuracy improvements (error rate reduction in automated workflows)
- Processing speed gains (cycle time versus baseline)
Budgets align with realized value — if the results don't materialize, neither does the full cost.
Works best when: Business results are clearly measurable upfront and the enterprise wants cost tied directly to demonstrated impact rather than activity.
Key Factors That Drive Enterprise GenAI Costs
Pricing model selection is just the starting point. The real cost drivers are technical, operational, and organizational — and they compound quickly at enterprise scale.
Model Complexity and Capability Tier
Frontier large models used for complex reasoning, multi-modal tasks, or code generation cost far more per token than smaller, task-specific models. The cost difference is substantial:
| Model Tier | Example Models | Cost Range (Output/MTok) | Use Cases |
|---|---|---|---|
| Frontier | GPT-4o, Claude 3 Opus | $15.00–$30.00 | Complex reasoning, multi-step workflows |
| Mid-Tier | GPT-4o-mini, Claude 3.5 Sonnet | $3.00–$15.00 | Balanced performance and cost |
| Economy | Gemini Flash-Lite, Claude 3 Haiku | $0.40–$1.25 | High-volume, simple tasks |
The frontier-to-economy cost ratio can be 25–50x depending on vendor. Organizations often overspend by defaulting to frontier models when mid-tier or economy models would suffice for specific tasks.
Scale, Volume, and Workload Characteristics
Cost scales non-linearly with usage. High-volume, real-time workloads like customer-facing chatbots or automated document processing face infrastructure and throughput costs that batch or low-volume workloads avoid. Moving from pilot to full production deployment requires 250–400% more investment than the pilot phase, largely due to security hardening and compliance documentation.
Inference cost now dominates AI spending. Google reportedly spends 10–20x more on inference than on model training, and inference accounts for 80–90% of total AI spend for agentic systems. Cloud bills can spike from $5,000 to $50,000 monthly when transitioning from pilot to production volumes.
Customization, Fine-Tuning, and Integration Depth
Out-of-the-box models cost least. Each step up in customization changes the cost profile:
- RAG-based implementations add retrieval infrastructure costs
- Fine-tuned models add training compute costs
- Deeply integrated custom solutions add engineering, data pipeline, and ongoing maintenance expenses
Piloting at small scale first — validating actual cost-per-outcome before committing to enterprise-wide contracts — is what separates controlled spending from budget overruns. This is the core principle behind Codewave's QuantumAgile™ approach.
Compliance, Governance, and Data Residency Requirements
Regulated industries face material compliance premiums. Costs include data privacy controls, audit trail infrastructure, explainability frameworks, and in some cases dedicated hosting to meet data residency mandates.
Compliance cost premiums by industry:
- Regulated industries (finance, healthcare, insurance): 15–25% of total project cost
- Non-regulated industries: 5–10% of total project cost
In healthcare specifically, compliance overhead can multiply operational costs by 3–5x beyond raw inference costs. A support agent costing $10,000/month in standard inference can cost $35,000/month once compliance infrastructure is added. Implementing explainability using libraries like SHAP or LIME can double compute resources and latency.

Hidden Costs That Blow Enterprise GenAI Budgets
Enterprise GenAI implementations routinely cost significantly more than vendor quotes suggest. 60% of AI projects exceed original estimates by 30–50%, often due to compliance remediation and undisclosed integration work. In practice, true total cost of ownership runs 2–4x the list price — across three recurring cost categories that most vendors never mention.
Data Preparation and Quality
Most enterprises begin AI projects without sufficient clean, labeled training or retrieval data. Unplanned data work is one of the largest budget overruns. Gartner predicts that through 2026, organizations will abandon 60% of AI projects due to lack of "AI-ready" data.
Budget impact:
- Data preparation typically accounts for 10–20% of total AI budget
- In data-heavy use cases, this reaches 30–40% of total project cost
- Poor data quality costs companies an average of $12.9 million per year, according to Gartner research
Organizations that get AI right invest up to 4x more in data quality and governance upfront — making it the single highest-leverage place to reduce downstream budget surprises. Integration complexity adds another layer of cost that compounds this problem.
Integration and Middleware Costs
Connecting GenAI to legacy ERP, CRM, or domain-specific systems requires significant engineering. Enterprises spend 30–40% of IT budgets managing complexity created by unintegrated applications.
Cost factors:
- Ongoing maintenance consumes 30–50% of total integration budget (Forrester)
- Custom integrations at scale exceed $500,000 annually for organizations managing 20+ connections
- The average enterprise runs 897 applications — only 29% of which are currently integrated
Using an integration platform as a service (iPaaS) can reduce TCO by 40–60% compared to custom-coded integrations. Even with iPaaS tooling, the integration burden rarely disappears — it shifts into model maintenance and monitoring costs over the production lifecycle.
Ongoing Model Maintenance and Drift Correction
Production AI models degrade over time as data distributions shift. 91% of machine learning models experience degradation over time (MIT research), and 75% of businesses observe AI performance declines without proper monitoring. Models unchanged for six months or longer see error rates jump by 35% on new data.
Annual maintenance costs:
- Enterprise-grade monitoring tools: $60,000–$200,000 annually
- In-house monitoring infrastructure: $400,000–$600,000 per year in engineering overhead
- General ongoing overhead: 15–30% of initial build cost every year
Across all three categories, the pattern is consistent: the upfront contract price is just the entry point. Teams that plan for these compounding costs from day one avoid the mid-project scrambles that kill ROI.

How to Choose the Right Pricing Model and Budget Accurately
Match the pricing model to the workload shape first, not to the lowest per-unit price. Here's the mapping:
Pricing Model Decision Framework:
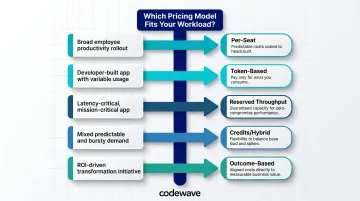
- Use per-seat pricing for broad employee productivity rollouts
- Use token-based pricing for developer-built apps with variable, unpredictable usage
- Use reserved throughput when latency and uptime are non-negotiable
- Use credits or hybrid plans when workloads mix predictable baselines with bursty demand
- Use outcome-based pricing for transformation initiatives where ROI is the primary metric
Building a Realistic Budget
Start with vendor quotes, then layer in hidden costs:
- Add 25–40% for integration, data preparation, and change management
- Add 15–20% annually for model maintenance and retraining
- Add compliance premium for regulated environments (15–25% of project cost)
Before committing at scale, validate AI's actual cost-per-outcome through a pilot. Codewave uses this approach with enterprise clients to surface pricing mismatches early — before long-term contracts lock in assumptions that real-world usage quickly disproves.
Cross-Functional Budget Ownership
Effective AI pricing decisions involve:
- Finance: Predictability needs and budget compliance
- Engineering: Workload modeling and technical requirements
- Operations: Process integration and change management
When these functions operate in silos, each team optimizes for different metrics — Finance caps spend, Engineering underestimates scale, Operations ignores migration costs. The result is predictable: budget overruns and mid-project renegotiations. Shared ownership from the start closes that gap before it opens.
What Most Enterprises Get Wrong About GenAI Pricing
The most damaging mistake: comparing vendors on a single metric—token price or seat cost—without modeling what those units mean under real workload conditions. Two vendors with identical list rates can produce 3–5x cost differences in production depending on:
- Prompt design efficiency
- Model tier selection
- Caching strategy
- Batching capability
Example: Effective caching strategies can reduce model serving costs by up to 90%. OpenAI's prompt caching reduces input token costs from $5.00 to $0.50 per million tokens for GPT-5.5. Yet many enterprises never implement caching, paying 10x more than necessary.
Batch processing offers 50% discounts across all major providers, but only applies to asynchronous workloads. Organizations that default to real-time processing for tasks that could run overnight pay double unnecessarily.
The second most costly mistake: treating the subscription or API fee as the total cost. Enterprises that skip budgeting for hidden cost layers frequently discover their "affordable" GenAI pilot becomes prohibitively expensive to scale:
- Data preparation and labeling
- System integration and API management
- Ongoing governance and compliance overhead
- Model monitoring and maintenance
Without accounting for these, pilots stall at proof-of-concept — or trigger emergency re-procurement once leadership sees the real numbers.
Only 15% of generative AI users currently achieve significant, measurable ROI, according to Deloitte. Cost management discipline and a focus on long-term value — not upfront price — separates the 15% who see real returns from those still chasing them.
Conclusion
Enterprise GenAI pricing is complex because enterprise AI workloads are complex. There is no universal right model, only the model that fits the workload shape, organizational maturity, and ROI expectations of a specific deployment. Organizations that succeed are those that look beyond list prices to model actual usage patterns, account honestly for hidden costs, and pilot at small scale before committing to enterprise-wide contracts.
The right cost framework balances short-term budget predictability with long-term value delivery. Organizations that account for data preparation and integration costs upfront, then measure success in outcomes rather than usage volume, extract more value from their GenAI investments than those chasing lower per-token rates.
With enterprise AI spending projected to hit $644 billion in 2025, pricing model selection has moved well past procurement. Get it right, and the investment compounds. Get it wrong, and you have another pilot that never scaled.
Frequently Asked Questions
How much does Enterprise AI cost?
Enterprise GenAI costs range from under $100,000/year for basic SaaS deployments to $1–2 million+ for advanced custom implementations. The final figure depends heavily on pricing model, scale, customization depth, and industry compliance requirements.
What are the 4 types of pricing in enterprise GenAI?
The primary pricing models are per-seat subscription (flat fee per user), token/usage-based (cost per text processed), reserved throughput (fixed capacity commitment), and outcome/value-linked (payment tied to business results). Hybrid models combining these elements are increasingly common.
What is the difference between token-based and per-seat pricing for enterprise GenAI?
Per-seat pricing charges a flat monthly fee per user and suits predictable productivity use cases, while token-based pricing charges per unit of text processed and suits variable, developer-built application workloads. The key tradeoff is predictability versus flexibility.
What hidden costs should enterprises budget for when implementing GenAI?
The most significant hidden costs include:
- Data preparation and quality: 10–40% of project cost
- System integration engineering: 30–50% of integration budget for ongoing maintenance
- Compliance and governance infrastructure: 15–25% in regulated industries
- Ongoing model maintenance: 15–30% of initial build cost annually
Budget an additional 25–40% on top of initial vendor quotes to cover these reliably.
When does outcome-based pricing make sense for enterprise AI?
Outcome-based pricing works best for strategic transformation initiatives where business results are clearly measurable and the enterprise wants to shift delivery risk to the implementation partner. When those conditions are met, vendor incentives stay locked to your actual outcomes rather than project hours.
How can enterprises reduce their generative AI costs without sacrificing performance?
The highest-impact cost levers are:
- Smaller, specialized models for tasks that don't require frontier capability
- Batch processing for non-real-time workloads (typically a 50% discount)
- Prompt caching to avoid redundant computation (up to 90% savings)
- Right-sized pricing models matched to actual usage, not peak theoretical demand